I've been trying to dissect OpenID and make sure I really understand what's happening. The spec is the ultimate source, but obviously covers all the bases. What I wanted was a picture, but I couldn't find one. So, I made one.
Part of the problem with understanding the spec is that the text tells what has to happen, but there are some implementation details which, while variable, as still helpful for decoding the ins and outs of the most common scenarios. For implementation details, I turned to a Web proxy to help capture the HTTP request/response pairs. The one I used was called Charles Web Debugging Proxy. It's quite good and runs on all the major platforms. As shareware goes, it's a little steep for what it does: $50. Half that would be more like it. Still it did the job admirably.
So, from the spec and my poking around, I came up with the following scenario for what I deem to be the most common use case. Note that in OpenID parlance, the relying party is called the "consumer" and the identity provider is called the "OpenID server." I've tried to stick to the OpenID terminology where I can.
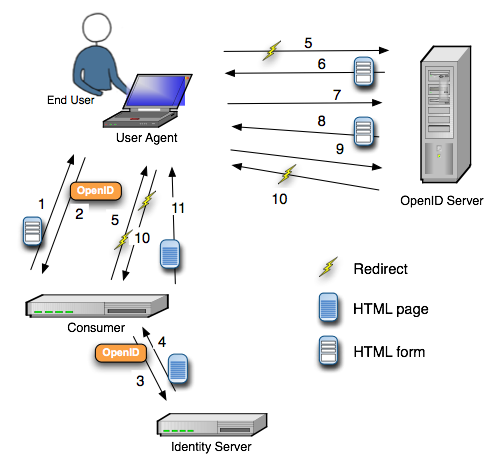
- User is presented with OpenID login form by the Consumer
- User responds with the URL that represents their OpenID
- Consumer canonicalizes the OpenID URL and uses the canonical version to request (GET) a document from the Identity Server.
- Identity Server returns the HTML document named by the OpenID URL
- Consumer inspects the HTML document header for <link/> tags with the attribute rel set to openid.server and, optionally, openid.delegate. The Consumer uses the values in these tags to construct a URL with mode checkid_setup for the Identity Server and redirects the User Agent. This checkid_setup URL encodes, among other things, a URL to return to in case of success and one to return to in the case of failure or cancellation of the request
- The OpenID Server returns a login screen.
- User sends (POST) a login ID and password to OpenID Server.
- OpenID Server returns a trust form asking the User if they want to trust Consumer (identified by URL) with their Identity
- User POSTs response to OpenID Server.
- User is redirected to either the success URL or the failure URL returned in (5) depending on the User response
- Consumer returns appropriate page to User depending on the action encoded in the URL in (10)
This scenario assumes that you are not already logged into the OpenID server. Normally, you'd stay logged in there and so steps (6) and (7) would be unnecessary.
While this looks like a lot of back and forth, assuming you're already logged in, the user actually only sees one page in addition to the original login page. This page, which I call the trust form (I'm not sure it has an official name) asks the User if they want to trust the Consumer site (identifying it by URL).
This scenario also does nothing to address security in OpenID. For that, you'd better read the spec. There are some nuances to be understood.
If you're familiar with OpenID, I'd appreciate any feedback on the picture and scenario. I'd like to make it as correct and understandable as possible.



