Summary
This post describes how I used the scatter-gather pattern to move from a synchronous process for generating fleet reports to an asynchronous solution, avoiding some failures that were caused by load and short HTTP timeout values. The result is a system that is more reliable and scalable than the previous, request-based synchronous solution.
Introduction

Fuse is an open-source, connected-car platform that I used use to experiment with techniques for building a true Internet of Things.
Fuse is built on a platform that supports persistent compute objects, or picos. Picos are an Internet-native, reactive programming system that supports the Actor model. You program them using a rule language called KRL. You can read more about picos here.
Fuse sends a periodic (weekly for now) report to the fleet owner providing all the details of trips and fuel fillups for each vehicle in the reporting period. The report also aggregates the detail information for each vehicle and then for the fleet. Here's the start of a weekly report for my fleet:

The owner is represented by a pico, as are the fleet and each of the vehicles. Each of these picos is independent, network addressable, stores data for itself, and executes processes that are defined by functions and rules. They can respond to requests (via functions) or events (via rules). They communicate with each other directly without intermediation.
Synchronous Request-Response Solution
The most straightforward way to create a report, and the one I used initially, is for the fleet to make a request of each of its vehicles, asking them to compile details about trips and fillups and return the resulting JSON structure. Then the fleet formats that and sends an event to the owner pico indicating the report is ready to email. That process is represented by the following diagram. The methods for coding it are straightforward and will be familiar to anyone who's used an API.
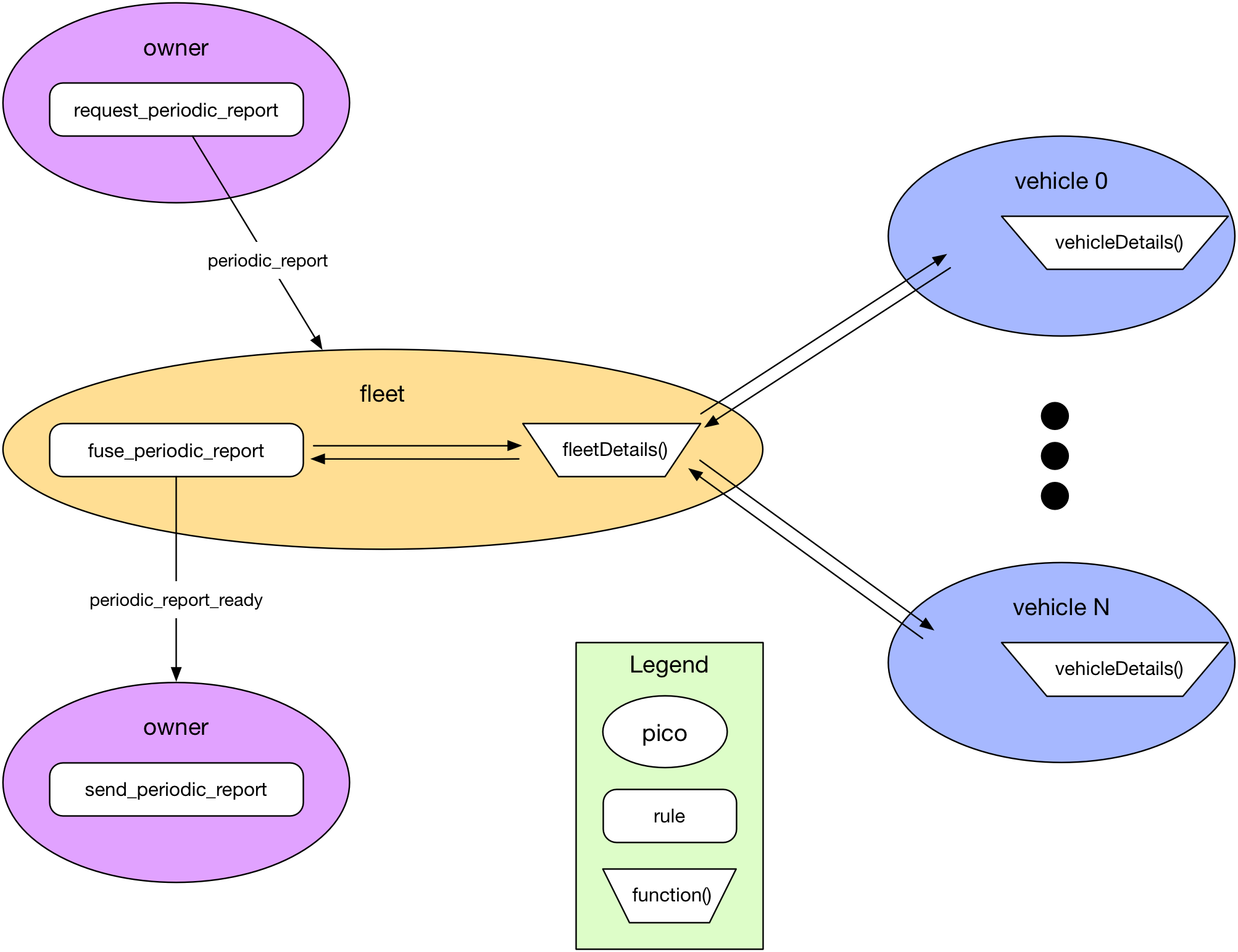
The owner pico kicks everything off by sending the periodic_report event to the fleet pico.
The fuse_periodic_report rule in the fleet pico calls a function in the fleet pico called fleetDetails() that makes synchornous requests to each of the vehicles over HTTP using their API. Once all the vehicles have responded, the rule formats the report and tells the owner pico its ready via the periodic_report_ready event.
This works pretty well so long as the vehicles respond in a timely manner. For performance reasons, I have the HTTP timeouts set fairly short, so any big delay causes a vehicle to get missed when a request for its details times out. For people with a few vehicles in their fleet, it's fairly rare for this to happen. But with lots of vehicles, the chances go up. Somewhere around 10 vehicles in the fleet and your chances of at least one vehicle timing out get fairly good.
If my only tool was synchronous request-response-style interactions, then this would be a pretty big problem. I could increase the time out, but that's a bandaid that will only mask the problem for a while. I could make the vehicleDetails() function more performant, but that's a lot of work for reasons having to do with how the underlying platform does queries in Mongo. So that's a can of worms I'd rather not open now. Besides, it's still possible for something to get delayed due to network latency or some other problem regardless of how fast the underlying platform is.
Scatter-Gather Solution
A more entertaining and intellectually interesting solution is to use a scatter-gather pattern of rules to process everything asynchronously.

Vaughn Vernon describes the scatter-gather pattern on page 272 of his new book Reactive Messaging Patterns with the Actor Model1. Scatter-gather is useful when you need to get some number of picos to do something and then aggregate the results to complete the computation. That's exactly the problem we face here: have each vehicle pico get its trip and fillup details for the reporting period and then gather those results and process them to produce a report.
The diagram below shows the interactions between picos to create the report. A few notes about the diagram:
- Each pico in the diagram with the same name is actually the same pico, reproduced to show the specific interaction at a given point in the flow.
- The rules send events, but only to a pico generally, not to a specific rule. Each pico provides an event bus that rules use to subscribe to events. Any number of rules can be listening for a given event.
- There are no requests (function calls) in this flow, only asynchronous events.

Here's how it works.
The owner pico kicks everything off by sending the request_periodic_report event to the fleet. Because events are asynchronous, after it does so, it's free to do other tasks. The start_periodic_report rule in the fleet pico scatters the periodic_vehicle_report event to each vehicle in the fleet, whether there's 1 or 100. Of course, these events are asynchronous as well. Consequently they are not under time pressure to complete.
When each vehicle pico completes, it sends a periodic_vehicle_report_created event to the fleet pico. The catch_vehicle_reports rule is listening and gathers the reports. Once it's added the vehicle report, it fires the periodic_vehicle_report_added event. Another rule in the fleet pico, check_report_status is checking to see if every vehicle has responded. When the number of reports equals the number of vehicles, it raises the periodic_report_data_ready event and the data is turned into a report and the owner pico is notified it's ready for emailing.
Some Messy Details
You might have noticed a few issues that have to be addressed in the preceding narrative.
First, while unlikely, it's possible that the process could be started anew before the first process has completed. To avoid clashes and keep the events and data straight, each report process has a unique report correlation number (rcn) Each report is kept separate, even if multiple reports are being processed at the same time. This is not strictly necessary for this task since reports run once per week and are extremely unlikely to overlap. But it's a good practice to use correlation numbers to keep independent process flows independent.
Second, the check_report_status uses events from the vehicle picos to determine when it's done. But event delivery is not guaranteed. If one or more vehicle picos fail to produce a vehicle report, then no fleet report would be delivered to the owner. There are several tactics we could use:
- We could accept the failure and tell owners that sometimes reports will fail, possibly giving them or someone else the opportunity to intervene manually and regenerate the report.
- We can set a timeout and continue, generating a report with some missing vehicles.
- We can set a timeout and reissue events to vehicle picos that failed to respond. This is more complicated because in the event that the vehicle pico still fails to respond after some number of retries, we have to adopt the strategy of continuing without the data.
I adopted the second strategy. Picos have the ability to schedule events for some future time (either once or repeating). I chose 2 minutes as the time out period. That's plenty long enough for the vehicles to respond.
This idea of creating timeouts with scheduled events is very important. Unlike an operating system, picos don't have an internal timer tick. They only respond to events. So it's up to the programmer to determine when a timer tick is necessary and schedule one. While it's possible to use recurring scheduled events to create a regular, short-delay timer tick for a pico, I discourage it because its generally unnecessary and wastes processing power.
Conclusion
Using the scatter-gather pattern for generating reports adds some complexity over the synchronous solution. But that point is moot since the synchronous solution fails to work reliably. While more complicated, the scatter-gather solution is only a handful of additional rules and none of them are very long (142 additional lines of code in total). Each rule does a single, easy-to-understand task. Using the scatter-gather solution for generating reports increases the reliability of the report generating system at an acceptable cost.
The scatter-gather solution makes better use of resources since the fleet pico isn't sitting around waiting for all the vehicles to complete before it does other important tasks. The fleet pico is free to respond to other events that may come up while the vehicles are completing their reports.
The concurrent processing is done without locks of any kind. Because each pico is independent, they have no need of locks when operating concurrently. The fleet pico could receive events from multiple vehicles, but they are queued and handled in turn. Consequently, we don't need locks inside the pico either. Lockless concurrency is a property of Actor-model systems like picos.
In general, I'm pretty happy with how this works and it was fun to think about. Next time I'm faced with a similar problem, scatter-gather will be my first choice, not the one I use after the synchronous solution fails.
Notes
- I recommend Vaughn's book for anyone interested in picos. While the language/framework (Scala and Akka) is different, the concepts are all very similar. There's a lot of good information that can be directly applied to programming picos.



