Summary
This is an introduction to picos as a method for doing reactive programming. The article contains many links to other, more detailed articles about specific topics. You can thus consider this an index to a detailed look at how picos work and how they can be programmed.
Updated to include discussions about identity and KRL.

The Reactive Manifesto describes a type of system architecture that has four characteristics (quoting from the manifesto):
- Responsive: The system responds promptly if at all possible.
- Resilient: The system stays responsive in the face of failure.
- Elastic: The system stays responsive under varying workload.
- Message Driven: Reactive Systems rely on asynchronous message-passing to establish a boundary between components that ensures loose coupling, isolation, location transparency, and provides the means to delegate errors as messages.
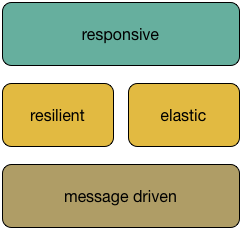
These are often represented as a stack since the only explicit architectural choice is to be message driven. The others are emergent properties of that and other architectural choices.
The goal of the reactive manifesto is to promote architectures and systems that are more flexible, loosely-coupled, and scalable while making them amenable to change. The manifesto doesn't specify a development methodology so reactive systems can be built using a wide variety of systems, frameworks, and languages.
Persistent Compute Objects
Persistent compute objects (picos), are a good choice for building reactive systems—especially in the Internet of Things.
Picos implement the actor model of distributed computation. Actors extend message-driven programming with two additional required properties. In response to a received message,
- actors send messages to other actors
- actors create other actors
- actors implement a state machine that can affect the behavior of the next message received
This is also a good, high-level description of the properties that picos have. Picos respond to events and queries by running rules. Depending on the rules installed, a pico may raise events for itself or other picos. Picos can create and delete other picos. Each pico has a persistent data store that can only be affected by rules that run in response to events. I describe picos and their API and programming model in more detail elsewhere. Event-driven systems, like those built from picos, are the basis for systems that meet the reactive manifesto.
Picos support direct asynchronous messaging by sending events to other picos. Also, picos implement an event bus internally. Events sent to the pico are placed on the internal event bus. Rules in the pico are selected to run based on declarative event expressions. The pico matches events on the bus with event scenarios declared in the event expressions. Event expressions can specify simple single event matches, or complicated sets of events with temporal ordering.
Picos share nothing with other picos except through messages exchanged between them. Picos don't know and can't directly access the internal state of another pico.
As a result of their design, picos exhibit the following important properties:
- Lock-free concurrency—picos respond to messages without locks.
- Isolation—State changes in one pico cannot affect the state in other picos.
- Location transparency—picos can live on multiple hosts and so computation can be scaled easily and across network boundaries.
- Loose coupling—picos are only dependent on one another to the extent of their design.
Channels and Messaging
Pico-to-pico communicate happens over event channels. Picos have many event channels. An event channel is point-to-point and delivers events directly to the pico. Picos can only interact by raising events and making requests on a specific event channel.
Picos can only get an event channel to another pico in one of four ways:
- Parenthood—when a pico creates another pico, it is given the only event channel to that new child pico.
- Childhood—when the parent creates a child, the child receives an event channel to its parent1.
- Endowment—as part of the initialization, a parent pico can give channels in its possession the child.
- Introduction—one pico can introduce a second pico to a third. In addition, the OAuth flow supported by picos returns a channel to the pico.
Children only have a channel to their parent, unless (a) the parent gives them other channels during initialization, (b) the parent introduces them to another pico, or (c) they are capable of creating children. Consequently, a pico is completely isolated from any interaction that its parent (supervisor) doesn't provide. This creates a security model similar to the object capability model.
Applications
A pico-based application is a collection of picos operating together to achieve some purpose. A single pico is almost never very interesting.
Picos live inside a host called KRE2. KRE is the engine that makes picos work. A given instance of KRE can host many picos. And there can be any number of KRE instances. Picos need not exist in the same instance of KRE to interact with each other.
When an account is created in KRE, a root pico is also created. That pico is special in that it is directly associated with the account and cannot be deleted without deleting the account. Only the root pico can be introduced to another application via OAuth. The root pico can create children, and those picos can also create children.
For example, in Fuse, the connected-car application we built using picos, each Fuse owner ends up with a collection of picos that look like this:
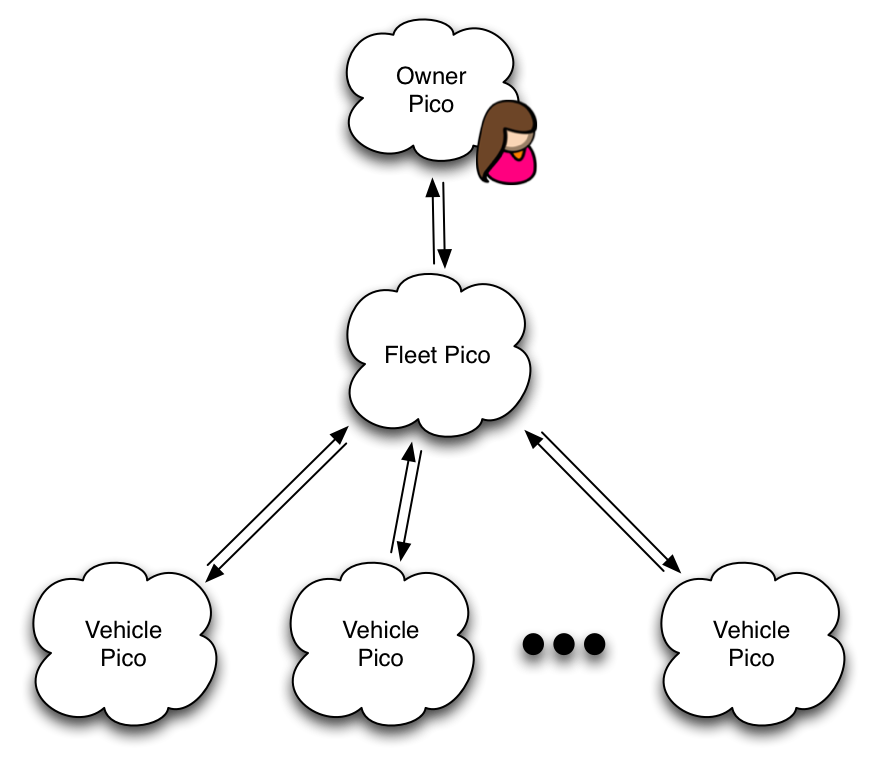
The Fuse application isn't a single pico, but a collection. Fuse arranges picos in a particular configuration and endows them with specific functionality to create the overall experience. The owner pico is the root pico in the account. When it's created and initialized, it created a fleet pico. The fleet pico creates vehicle picos as necessary as people manipulate the mobile application to add a new vehicle.
Picos belong to a parent-child hierarchy with every pico except for the root pico having a parent. Further, each child pico in the hierarchy belongs to the same account as the root pico. Picos can be moved from one account to another although KRE does not yet support this.
The parent-child relationship is important because the parent installs the initial rules in the child, imbuing it with functionality and then initializes the pico to give it relationships to other picos and set its initial state. Since the parent is installing rules of its choosing, initialization consists of installing the initialization rule and then sending the child pico an event that causes the initialization rule to fire.
But, the collection of picos that make up an application need not communicate hierarchically or even within the picos of a single account. The channels that link picos create the relationships that allow the application to work
For example, consider the following diagram, again from Fuse:
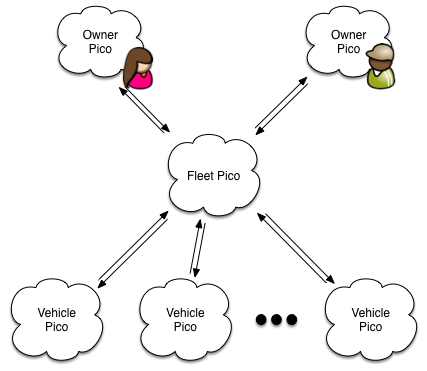
In this diagram, the fleet pico has two owners. That is, there are two picos that have owner rights for the fleet. The two owners are in different accounts and could be on different KRE hosts. The behavior of the application depends on the pico relationships represented by the arrangement of channels, channel attributes, and the rules installed in each pico. Because there's no fixed schema or configuration of picos, the overall application is very dynamic and flexible.
Each pico presents a potentially unique API based on the rulesets it contains. Mobile and web-based applications communicate with the pico and use its API using a model called the pico application architecture (PAA).
Internet First
Picos were developed to be Internet-centric:
- Picos are always online. Picos don't crash, and they only go away when explicitly deleted. Picos can be programmatically deleted or when the account they are in is deleted.
- Rulesets are loaded by URL. There is a registry that associates a short-name (called the ruleset ID) with the URL, but KRE only caches the ruleset. The definitive source is always the ruleset specified by the URL.
- Channels are URLs. Events are raised using the URL. This is primarily done over HTTP, although a SMTP gateway exists and KRE could support other transport mechanisms such as MQTT.
Being first-class Internet citizens sets picos apart from other actor-based programming tools used to build resilient systems. The Internet-centric design supports Internet of Things applications and means that pico-based systems inherently support the important properties that set the Internet apart including decentralized operation, heterarchical structure, interoperability of components, and substitutability of servers.
Identity
Scattered throughout the preceding discussion are numerous references to identity issues, including authentication and authorization. Picos free developers from worrying about most identity issues.
Picos have a unique identity that is the basis of their isolation. Persistent data is independently stored for each pico without special effort by the developer. A channel is owned by only one pico. Rulesets are installed on a pico-by-pico basis.
Each root pico is associated with a single account. And descendents of the root pico are owned by the same account. The account handles authentication, including OAuth access, for any picos in the account. KRE implements the account identity layer.
Clients can use the OAuth flow to get access to a channel for the root pico. Access to another pico in the account is mediated by rulesets installed in the root pico. The client (i.e. relying party) can be a mobile application, Web application, or an online service. KRE acts as the authorization server, and the pico acts as the resource server. The resource is the pico's API.
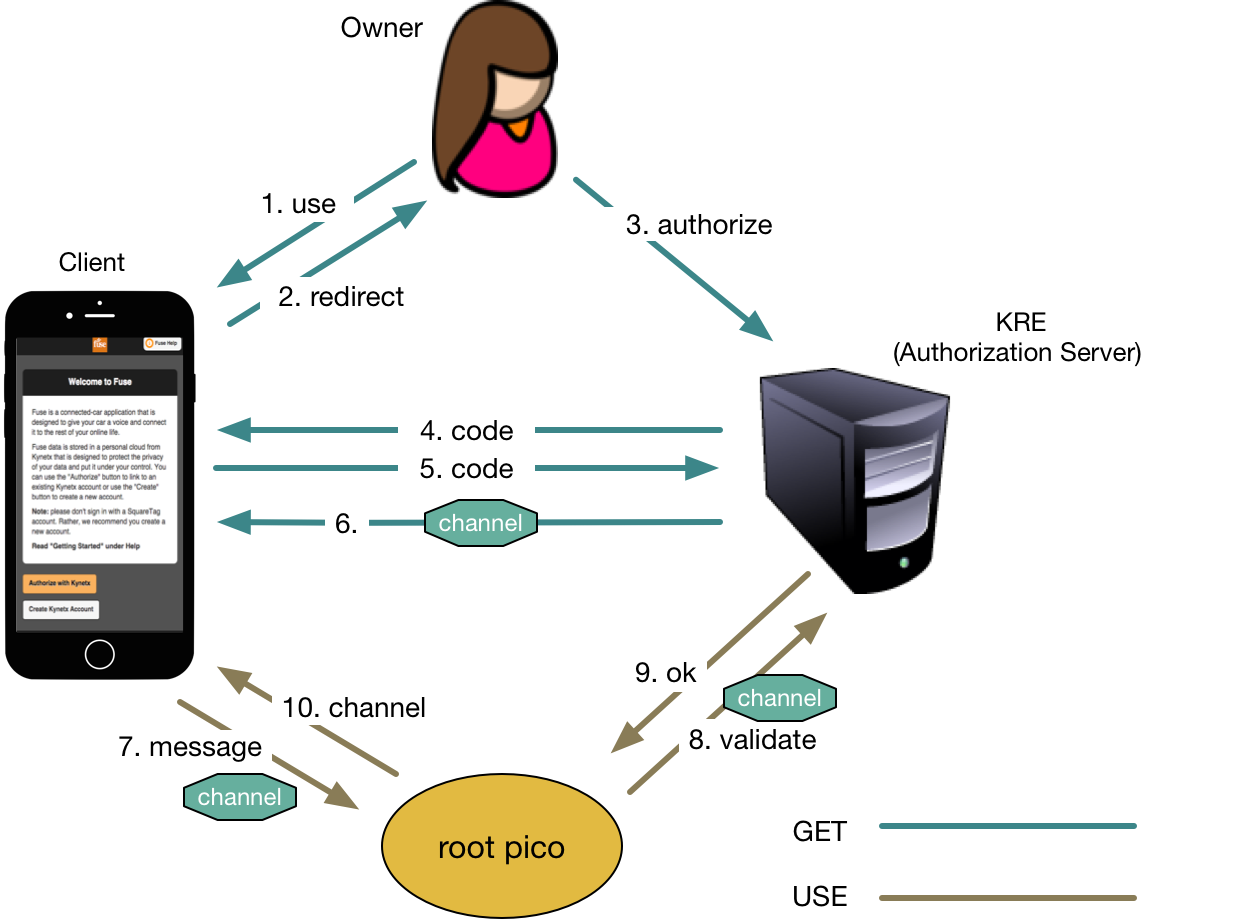
Giving out a channel is tantamount to giving permission to the holder to send events. Future versions of the system will support policies on channels that restrict interactions. But for many uses (e.g. the Fuse connected car application) such restrictions are unnecessary since the only systems with access to channels were all under the account owner's control.
Reactive Programming with Picos
Picos present an incredibly flexible programming model. In particular, since picos can programmatically create other picos, form relationships with other picos by creating and sharing channels, and change their behavior by installing and uninstalling rulesets, they can be very dynamic.
There are several important principles that you should remember when using picos to create a reactive system.
Think reactively. Picos are much more responsive and scalable when programmed with events. While picos can query other picos to get data snapshots, queries can lead to excessively synchronous operation. Because picos support lock-free asynchronous concurrency, they are more efficient when responding to events to accomplish a task. But this requires a new way of thinking for developers who have traditionally programmed in object-oriented and imperative languages. As an example, I've described in detail how I converted a report generation tool for Fuse from a synchronous request-response system to one based on the scatter-gather pattern. The reactive solution is more resilient because it's designed to accommodate failure and missed messages. Moreover, the reactive solution is more scalable because it doesn't block and thus isn't subject to timeouts:
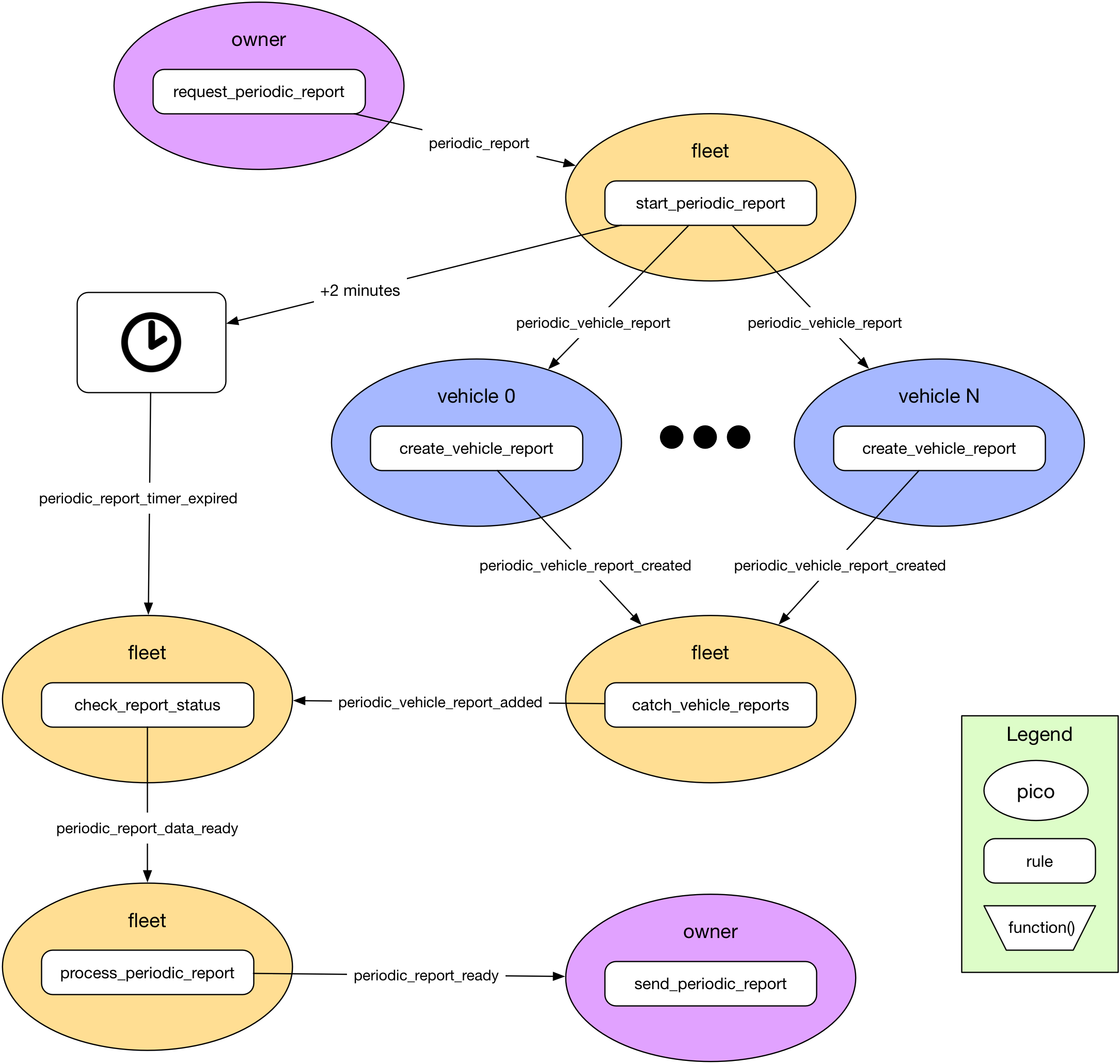
Use picos to create the model. Picos represent individual entities since they have a unique identity and are persistent. They can have unique behavior and present their own API to other picos and applications. The overall structure of a system of picos should correspond to the relationships that entities have in the modeled system.
In Fuse, as we've seen, there are picos that represent the owner (a person), the fleet (a concept and collection), and each vehicle (a physical device). Picos were designed to build models for the Internet of Things, but they can be used for other models we well. For example, we used picos to model a guard tour system that included entities as diverse as locations and reports:

Think in interactions. Going along with the idea of modeling with picos, developers have to think in terms of the interactions that picos have with each other. While the rulesets installed in each pico defines its behavior, the behavior of the application derives from the interaction that the picos have with each other. Developers can use tools like pico maps that show those relationships and swim-lane diagrams that show the interactions that happen in response to events.
In addition to the interactions between picos, the rules in a single pico are responsive to events and often raise an event to the same pico, causing other rules to respond. For example, this diagram shows the interactions of a few rules in a vehicle pico in response to a single pds:profile_updated event:

You can see from the diagram, that the single event sets off a chain of reactions, including sending events to other picos and calls to external APIs. You can read the details in Fuse as a Microservice Architecture.
Let the system do the scheduling and avoid blocking. When an event is raised in a pico, the pico event evaluation cycle picks rules to run based on their event expressions and schedules them.

Developers can order rule evaluation inside a pico through the use of events, event expressions, and ad hoc locks using persistent storage. Between picos, controlling order is even harder. In general, avoid using these to sequence operations as much as possible and let the system do the scheduling.
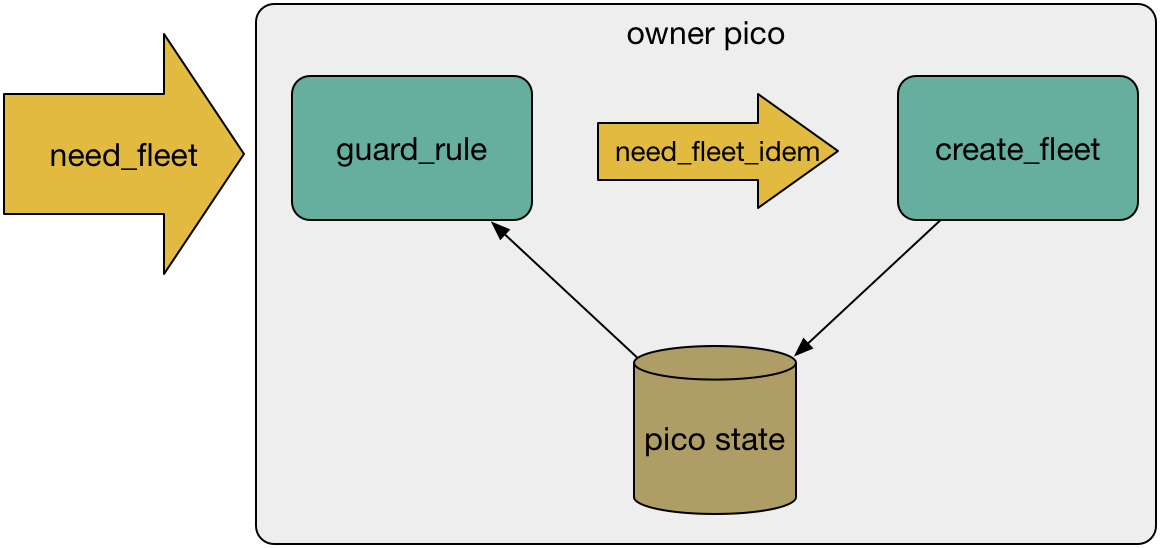
Use idempotency. Failure is easier to handle when picos are not sensitive to repeated delivery of the same event since they are free to retry without having to determine if the previous event completely partially or was been delivered. Many operations are naturally idempotent. For those that aren't, the pico can often create guard rules that assure idempotency. Since one pico can't directly see another pico's state, the receiving pico must take the responsibility for idempotency. Idempotent Services and Guard Rules provides more detail, including an example:
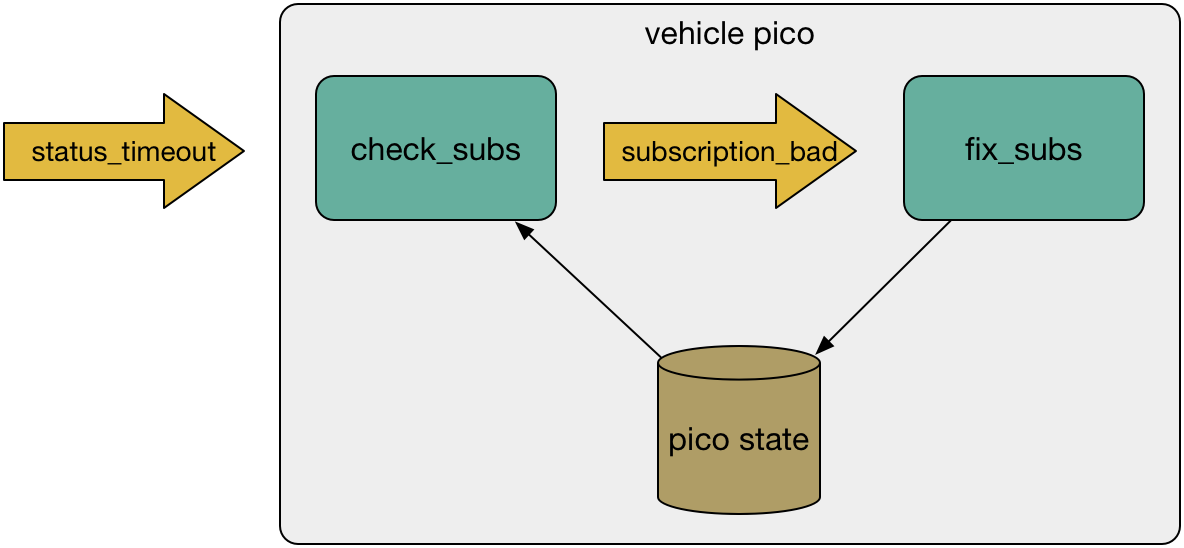
Be resilient. Developers can't anticipate every situation, but picos can be modified over time to be resilient to common failure modes. Picos have a number of methods for handling errors including the ability to set default rulesets for error handling and the ability to select rules based on error conditions. In addition, because pico-based applications are incredibly dynamic, they can frequently be programmed to self-heal. For example, A Microservice for Healing Subscriptions describes how a simple rule can check for missing channels and recreate them:
Whither KRL?
If you've had a prior introduction to picos, you might be wondering about KRL, the rule language used to program picos. How is it that I managed to write a long post about reactive programming and picos without mentioning KRL?
Picos relate to KRL in a way analogous to the relationship between Unix and C. I can talk about Unix programming, processes, file systems, user IDs, scheduling, and so on without ever mentioning C. Similarly, I can talk about reactive programming and picos without explicitly mentioning KRL.
Does that mean KRL isn't important? On the contrary, there's no other way to program picos. But building a pico-based application isn't so much about KRL as it is the function, behavior, and arrangement of the picos themselves.
People often ask if we couldn't just get rid of KRL and use JavaScript or something else. The answer is a qualified "yes." The qualification is that to get pico functionality, you need to add event expressions, persistent data, a runtime environment, accounts and identifiers, channels, and the ability to manage the pico lifecycle dynamically, including the JavaScript installed in each one. By the time you're done, JavaScript is a very small part of the solution.
For most people, learning KRL isn't going to be the hard part. The hard part is thinking reactively. Once you're doing that, KRL makes implementing your reactive design fairly easy and you'll find that its features map nicely to the problems you're solving.
Conclusion
Picos are a dynamic, actor-based system that support building reactive systems. The Internet-centric nature of picos means that they are especially suited to building Internet of Things applications that are decentralized and independent. All of the components that support building systems with picos are open source. I have a group of students helping to build, test, and use pico-based systems and further develop the model. We invite your questions, feedback, and help.
I found inspiration for writing this article and seeing actors as an answer to building reactive systems from Vaughn Vernon's book Reactive Messaging Patterns with the Actor Model: Applications and Integration in Scala and Akka.
- Strictly speaking, it isn't necessary for the child to automatically get the parent's channel and it may be better to let the parent supply that only if necessary. This may change in future versions of KRE. Let me know if you have feedback on this.
- KRE used to be an acronym for the Kynetx Rules Engine. Now, it's just KRE.



